‘Architecture’
Shared Nothing v.s. Shared Disk Architectures: An Independent View
Tuesday, November 24th, 2009
The Shared Nothing Architecture is a relatively old pattern that has had a resurgence of late in data storage technologies, particularly in the NoSQL, Data Warehousing and Big Data spaces. As architectures go it has some pretty interesting performance tradeoffs when compared to the more common approach of simply sharing a disk array (known as Shared Disk). This article compares and contrasts these two.
Shared Disk and Shared Nothing
Shared nothing is a simple idea. Data data is partitioned in some manner and spread across a set of machines. This means that each machine has sole access, and hence sole responsibility, for the data it holds. It does not share responsibility with other machines. So data is completely segregated, with each node having total autonomy over its particular subset.
By comparison shared disk is essentially the opposite: all data is accessible from all cluster nodes. Any machine can read or write any portion of data it wishes. See the figures below.
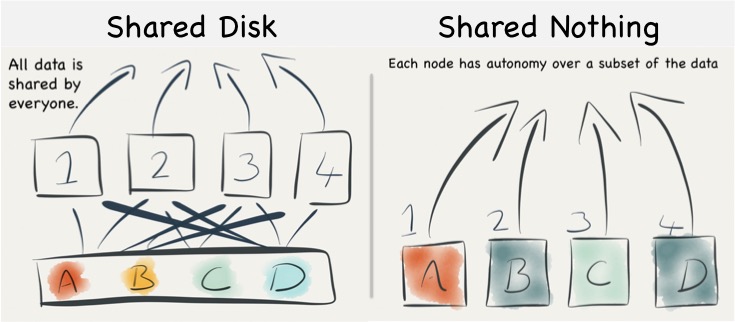
Understanding the Trade-offs for Writing
When persisting data in a shared disk architecture writes can be performed against any node. If node 1 and 2 both attempt to write a tuple then, to ensure consistency with other nodes, the management system must either use a disk based lock table or else communicated their intention to lock the tuple with the other nodes in the cluster. Both methods provide scalability issues. Adding more nodes either increases contention on the lock table or alternatively increases the number of nodes over which lock agreement must be found.
To explain this a little further consider the case described by the diagram below. The clustered shared disk database contains a record with PK = 1 and data = foo. For efficiency both nodes have cached local copies of record 1 in memory. A client then tries to update record 1 so that ‘foo’ becomes ‘bar’. To do this in a consistent manner the DBMS must take a distributed lock on all nodes that may have cached record 1. Such distributed locks become slower and slower as you increase the number of machines in the cluster and as a result can impede the scalability of the writing process.
The other mechanism, locking explicitly on disk, is rarely done in practice as caching is so fundamental to performance.
However shared nothing does not suffer from the same distributed locking problem, assuming that the client is directed to the correct node (that is to say a client writing ‘A’, in the figure above, directs that write at Node 1) , the write can flow straight though to disk with any lock mediation performed in memory. This is because only one machine has ownership of any single piece of data, hence by definition there only ever needs to be one lock.
Thus shared nothing can scale linearly from a write perspective without increasing the overhead of locking data items, because each node has sole responsibility for the data it owns.
However shared nothing will still have to execute a distributed lock for transactional writes that span data on multiple nodes (i.e. a distributed two-phase commit). These are not as large an impedance on scalability as the caching problem above, as they span only the nodes involved in the transaction (as apposed to the caching case which spans all nodes), but they add a scalability limit none the less (and they are also likely to be quite slow when compared to the shared disk case).
So shared nothing is great for systems needing high throughput writes if you can shard your data and stay clear of transactions that span different shards. The trick for this is to find the right partitioning strategy, for instance you might partition data for a online banking system such that all aspects of a user’s account are on the same machine. If the data set can be partitioned in such a way that distributed transactions are avoided then linear scalability, at least for key-based reads and writes, is at your fingertips.
The counter, from the shared disk camp, is that they can use partitioning too. Just because the disk is shared does not mean that data can’t be partitioned logically with different nodes servicing different partitions. There is much truth to this, assuming you can set up your architecture so that write requests are routed to the correct machine, as this tactic will reduce the amount of lock (or block) shipping taking place (and is exactly how you optimise databases like Oracle RAC).
Put another way – a shared disk implementation can be configured in a shared nothing mode. The difference here is just the physical placement of data. Shared disk is always network attached in some way, never local. So whilst remote disks can provide comparatively high throughput and good random IO performance they will do this at often greater monetary cost.
|
Considering the Retrieval of Data
The retrieval of data is a very different story, with different tradeoffs for each of these two approaches. Looking firstly at Shared Disk we find two significant drawbacks:
The first is the potential for resource starvation, most notably disk contention on the SAN/NAS drives. Shared disk means exactly that: all machines share the same disk array, and to some extent the same interconnect. Fortunately disk contention in a large shared disk system can be alleviated by partitioning. Data within the shared disk subsystem is often partitioned by its usage pattern (usually by moving tables onto different sections of the backing disk array). The problem with this approach is that it is manual: the data must be physically partitioned in advance.
The second issue is that caching is less efficient. Each machine in a shared disk system is likely to become involved (and hence have the requirement to cache) the whole dataset. This reduces the efficiency of the cache as cache misses are more likely. This is in stark contrast to the shared nothing approach where each machine only needs to cache the subset of the data that it owns. Thus caching can be far more effective in a shared nothing system.
Shared nothing is not without its flaws though. SN works brilliantly if the query is self sufficient – if each node can complete its ‘portion’ of the processing without needing data from any other node. However there will inevitably arise use cases where data from multiple nodes must be brought together or joined in some way. The implication is often that data, which may not be included in the final result, be shipped from one machine to another. This need to ship data between machines to ‘join’ can have a significant effect of overall query performance.
So the reality is that the number of queries requiring data shipping will depend on both the use case and the partitioning strategy. There are many cases where joins can be eliminated altogether by using Aggregates – for example in commercial search engines. However, for many general business use cases, for example ones with large related fact tables, some data shipping is often inevitable. As a result many shared nothing solutions recommend the use of fast 10GE networks.
Finally we should comment on the concurrency. Many key-value stores use shards and SN to provide very high levels of concurrency. This is achieved by routing user requests, via the sharding key, to the single machine that has the required data. This pattern is very efficient and the result is stores that provide extremely high levels of read and write throughput over a large, concurrent user base. This pattern is used heavily in large web applications via NoSQL.
What we must note is that the scalability of this pattern is only available for key-based access. It does not apply to more general processing in a shared nothing system. Any request that does not explicitly use the primary key must be broadcast to all machines (partitions). This presents a limit to the scalability for questions that do not consider the primary key. As a result many shared nothing systems, which support more general query workloads, show similar levels of concurrency to single node systems (5-10 is not uncommon).
So this is important enough to restate: Shared nothing is only linearly scalable for key-based access. The use of secondary indexes always results in every node being consulted. This limits scalability, certainly in terms of the number of concurrent requests that can be serviced. This is one of the reasons for many distributed key-value stores sticking to the very simple K-V contract.
The retort is that shared nothing reduces the amount of data stored per machine. Thus total data volumes can be higher, or conversely each query will be faster as the average dataset per query is reduced. This is why SN is favoured for Big Data systems like HBase, Map Reduce, Cassandra etc.
|
Complexity at Scale
A possibly less obvious benefit of shared nothing is to do with complexity at scale. Put simply, because of the autonomous nature, each node in a SN system has a relatively simple contract. It’s concerns are encapsulated in its own data partition. This means the software to manage failure can be simpler, behaving with little or no knowledge of it’s wider role in the cluster.
In contrast shared disk systems are fully open to the influence of other nodes. These couplings take the form of locks, with timeouts and relatively complex failure semantics. If we consider a failure in a shared disk system, the node is likely to have locks out on the underlying shared disk structure. These locks implicitly affect the other processing nodes and the system must go through a process of discovering the failed nodes, it’s locks and then releasing them or letting them timeout.
The shared nothing system only has to detect failure and promote the backup node (or similar depending on the failure strategy of the system). In fairness these problems are well understood, but often still misapplied and always bring, IMHO, a little more complexity to bare. Certainly the complexity of these issues seems to grow with the number of nodes and the heterogeneity of the deployment. This means SN often works best for very large installations.
So Which Should You Use?
If you are Google or Amazon then the simple, autonomous SN model will likely be attractive. Key-value based approaches will give you the concurrency you need to serve millions of users. The brute force, divide and conquer approach to data processing will provide the grunt needed to sift through datasets that require hundreds of machines to process.
If you are a business system that is unlikely to need more than two or three servers then the complexities of partitioning a complex domain model efficiently may outweigh the benefits. This is why many business databases such as those provided by Oracle and IBM tend to favour shared disk. Particularly considering a shared disk model can be partitioned to simulate at least some of the benefits of the shared nothing approach but within a shared disk system.
Often the choice is made for you by the implementation, and there may be other features besides the physical architecture that attract you to a certain product. Certainly shared nothing, as an approach, is increasing in popularity. Most of the NoSQL space is shared nothing. However many NoSQLs have blended models that include both sharding and replication as first class primitives. This complicates the picture.
Hadoop also provides a blended model. HDFS is really a type of shared disk but the execution model it uses is shared nothing. Computation is routed to the nodes where data lies, wherever this is possible. Composite models such as this can be attractive as they provide benefits from both approaches: a shared subsystem which spans the various machines in the cluster. A programming model that treats data and processing as shared nothing, with each node assuming an autonomous, local data subset. This provides the benefits of shared nothing’s scaling-through-autonomy but with the power to break from the model where needed. Clever!
So whilst the concept of shared nothing vs shared disk is relatively simple, there are a huge host of other factors that differentiate the data technologies of today. This is just one classifier. But it is a useful one, at least from the perspective of understanding how these different systems work under the hood.
Further Reading
There are a number of good papers on the subject. The infamous Michael Stonebraker was one of the early SN evangelists, back in the early 80’s. His paper The Case For Shared Nothing still makes good reading, even if it does skip some issues.
Also Shared-Disk vs. Shared Nothing by the makers of ScaleDB – a Shared Disk database. This paper makes the case for Shared Disk and enumerates the downsides of Shared Nothing.
The last paper presents the opposite view. How to Build A High Performance Data Warehouse is well written, mapping the pros and cons of each architecture. However don’t be sucked in by the academic URL. The authors are all affiliated with Vertica which is a commercial implementation from the Stonebraker camp, and the paper noticeably favours a Shared Nothing Columnar Architecture model, like the one used by Vertica. Never the less it’s a good read.
Finally there is a good section in Architecture of a Database System.
See also Elements of Scale and Are Databases a Thing of the Past?